IntentVizor: Towards Generic Query Guided Interactive Video Summarization
Abstract
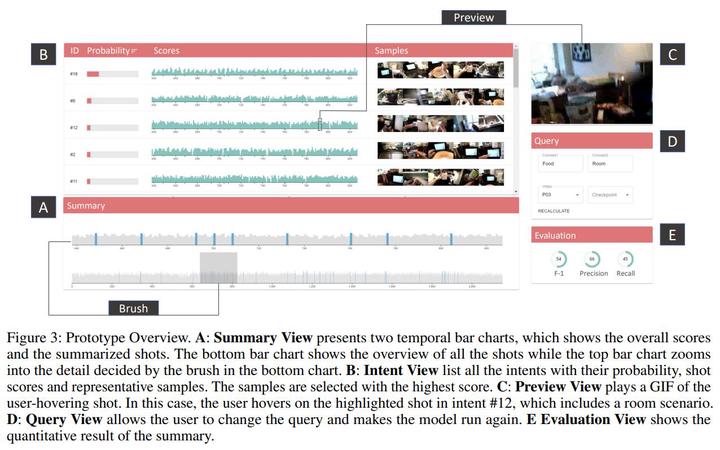
The target of automatic Video summarization is to create a short skim of the original long video while preserving the major content/events. There is a growing interest in the integration of user’s queries into video summarization, or query-driven video summarization. This video summarization method predicts a concise synopsis of the original video based on the user query, which is commonly represented by the input text. However, two inherent problems exist in this query-driven way. First, the query text might not be enough to describe the exact and diverse needs of the user. Second, the user cannot edit once the summaries are produced, limiting this summarization technique’s practical value. We assume the needs of the user should be subtle and need to be adjusted interactively. To solve these two problems, we propose a novel IntentVizor framework, which is an interactive video summarization framework guided by genric multi-modality queries. The input query that describes the user’s needs is not limited to text but also the video snippets. We further conclude these multi-modality finer-grained queries as user `intent', which is a newly proposed concept in this paper. This intent is interpretable, interactable, and better quantifies/describes the user’s needs. To be more specific, We use a set of intents to represent the inputs of users to design our new interactive visual analytic interface. Users can interactively control and adjust these mixed-initiative intents to obtain a more satisfying summary of this newly proposed interface. Also, as algorithms help users achieve their summarization goal via video understanding, we propose two novel intent/scoring networks based on the slow-fast feature for our algorithm part. We conduct our experiments on two benchmark datasets. The comparison with the state-of-the-art methods verifies the effectiveness of the proposed framework.
Guande Wu (吴冠德)
Applied Scientist II
Hi! This is Guande Wu, a Ph.D. student in Tandon School of Engineering, New York University. My advisor is Prof. Claudio T. Silva and I am also working with Prof. Chen Zhao. My research interest mainly lies in the user interface design and data visualization. Previously, I have worked with many outstanding experts in visualization at Zhejiang University, UC Davis and Microsoft Research Asia and Adobe Research.