Your Co-Workers Matter: Evaluating Collaborative Capabilities of Language Models in Blocks World
Abstract
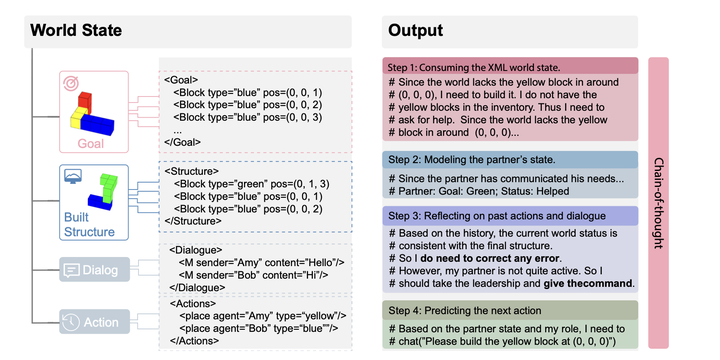
Language agents that interact with the world on their own have great potential for automating digital tasks. While large language model (LLM) agents have made progress in understanding and executing tasks such as textual games and webpage control, many real-world tasks also require collaboration with humans or other LLMs in equal roles, which involves intent understanding, task coordination, and communication. To test LLM’s ability to collaborate, we design a blocks-world environment, where two agents, each having unique goals and skills, build a target structure together. To complete the goals, they can act in the world and communicate in natural language. Under this environment, we design increasingly challenging settings to evaluate different collaboration perspectives, from independent to more complex, dependent tasks. We further adopt chain-of-thought prompts that include intermediate reasoning steps to model the partner’s state and identify and correct execution errors. Both human-machine and machine-machine experiments show that LLM agents have strong grounding capacities, and our approach significantly improves the evaluation metric.
Guande Wu (吴冠德)
Applied Scientist II
Hi! This is Guande Wu, a Ph.D. student in Tandon School of Engineering, New York University. My advisor is Prof. Claudio T. Silva and I am also working with Prof. Chen Zhao. My research interest mainly lies in the user interface design and data visualization. Previously, I have worked with many outstanding experts in visualization at Zhejiang University, UC Davis and Microsoft Research Asia and Adobe Research.